AI tools for ai influencer generator
Related Tools:
APOB AI Influencer Generator
APOB AI Influencer Generator is an AI tool that enables users to create personalized AI influencers or digital personas. Users can easily generate AI portraits and customize them with unique appearances, clothing, scenery, and styles for various purposes such as social media content creation, marketing campaigns, or brand representation. The tool offers a range of features to enhance AI portraits, including face swap, image to video conversion, and personalized prompts. APOB AI aims to empower users to unleash their creativity and engage with their audience through dynamic and engaging content.

Glambase
Glambase is an AI Influencer Generator that allows users to decide who's hot or not among AI influencers and shape the leaderboard. Users can create their own AI influencers with unique physical attributes and subscribe to the Glambase newsletter to stay up-to-date with the latest trends in the world of AI influencers.
MakeInfluencer AI
MakeInfluencer AI is a platform that allows users to create custom AI influencers to engage and monetize audiences with personalized interactions, driving real revenue. Users can design unique digital personas, generate content effortlessly, and monitor financial progress through a straightforward dashboard. The platform offers annual plans for creators to scale their AI empire, with features like face swaps and spicy roleplay chat. MakeInfluencer AI aims to revolutionize the influencer marketing industry by providing a user-friendly tool for creating and monetizing AI influencers.
AI Avatar Generator
AI Avatar Generator is a free tool that allows you to create amazing profile pictures and headshots in any setting using AI technology. With just a text prompt describing the image you want, the tool will generate a high-quality image that you can use for your social media profiles, website, or other purposes. You can also select from a variety of preset filters or create your own custom prompts to get the perfect image. AI Avatar Generator is a quick and easy way to create unique and professional-looking images for any occasion.
Glambase
Glambase is an AI Influencer Creation Platform that allows users to create personalized AI influencers with advanced customization options. Users can build virtual personas, interact with AI characters, and monetize their AI influencers. The platform offers a wide range of AI influencer models with diverse personalities and characteristics, catering to various preferences and needs of users. Glambase revolutionizes the way individuals engage with AI relationships and social media, providing a seamless and efficient solution for content creation and audience engagement.
Airshot
Airshot is an AI video generator application that allows users to create personalized brand videos for social media platforms. It offers features like transforming photos into trending videos, creating avatar videos, and a library of audience-favorite videos driven by social media data. The application uses AI technology to enhance videos with sexy AI girls, providing users with a professional videographer-like experience. Users can shoot videos without a camera, convert photos to videos, and explore a variety of video styles and gestures. Airshot aims to empower influencers and content creators by simplifying the video creation process and enhancing the visual appeal of their content.
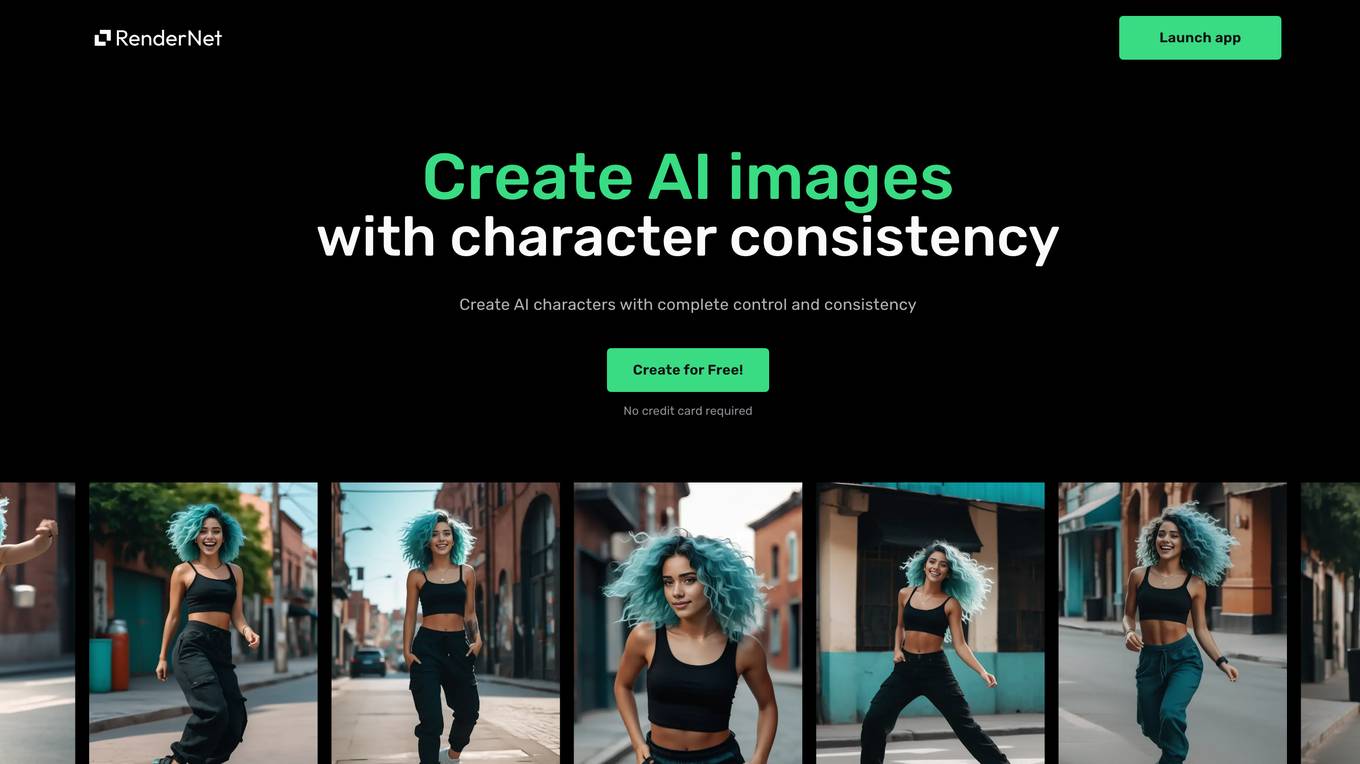
RenderNet AI
RenderNet AI is a powerful tool for generating character-driven images and videos with unparalleled control. It allows users to create unique characters, perfect poses, modify images seamlessly, upscale creations for realism, and narrate stories with lifelike voices. RenderNet offers advanced features like FaceLock, ControlNet, and multi-model generations, setting it apart in character design and customization. The application is free to use with a daily credit limit, and users can join a vibrant creator community to collaborate and share ideas.
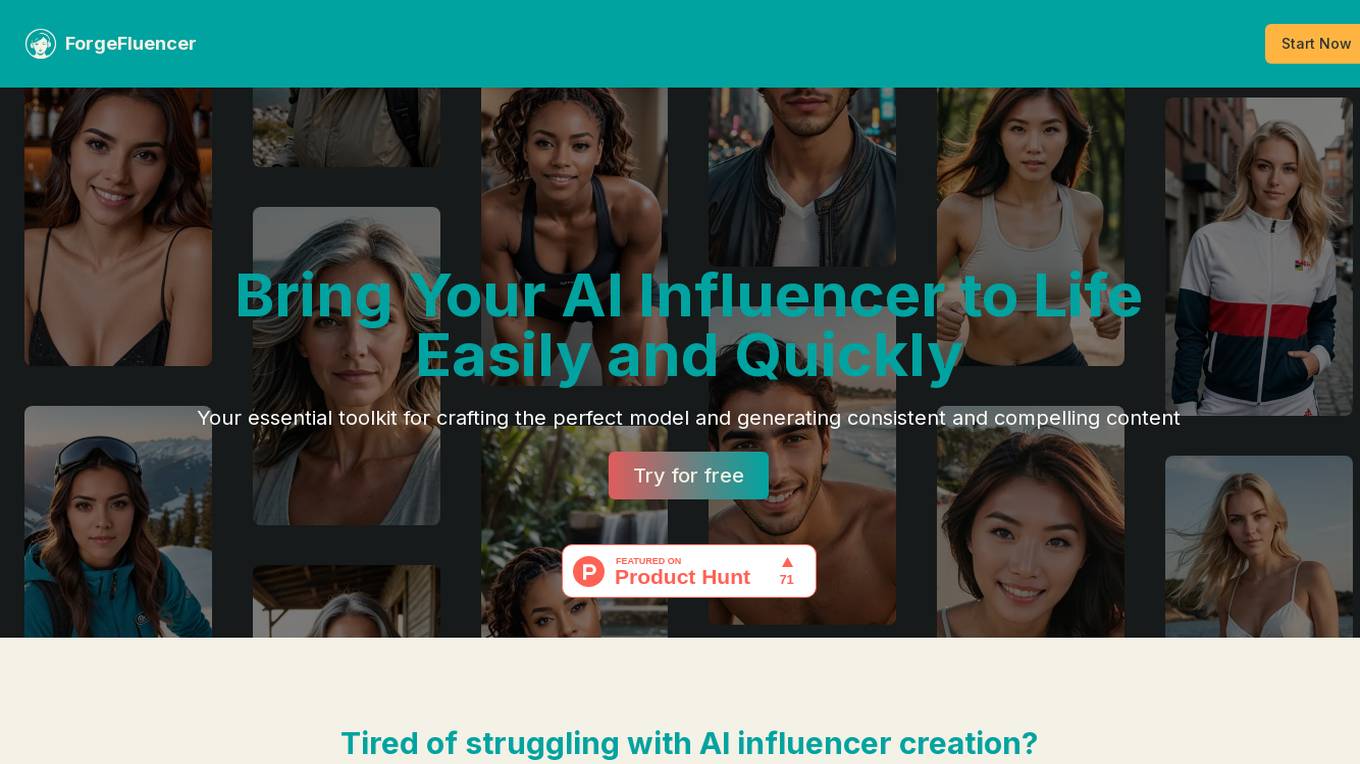
ForgeFluencer
ForgeFluencer is an AI application that serves as an essential toolkit for crafting AI influencers and generating consistent and compelling content. It offers a user-friendly platform optimized for desktop and mobile, allowing users to create models, control various aspects of content generation, edit images with AI, and more. With features like Virtual Wardrobe, Pose Controller, and Photo Studio, ForgeFluencer empowers users to elevate their projects with AI-generated content effortlessly.
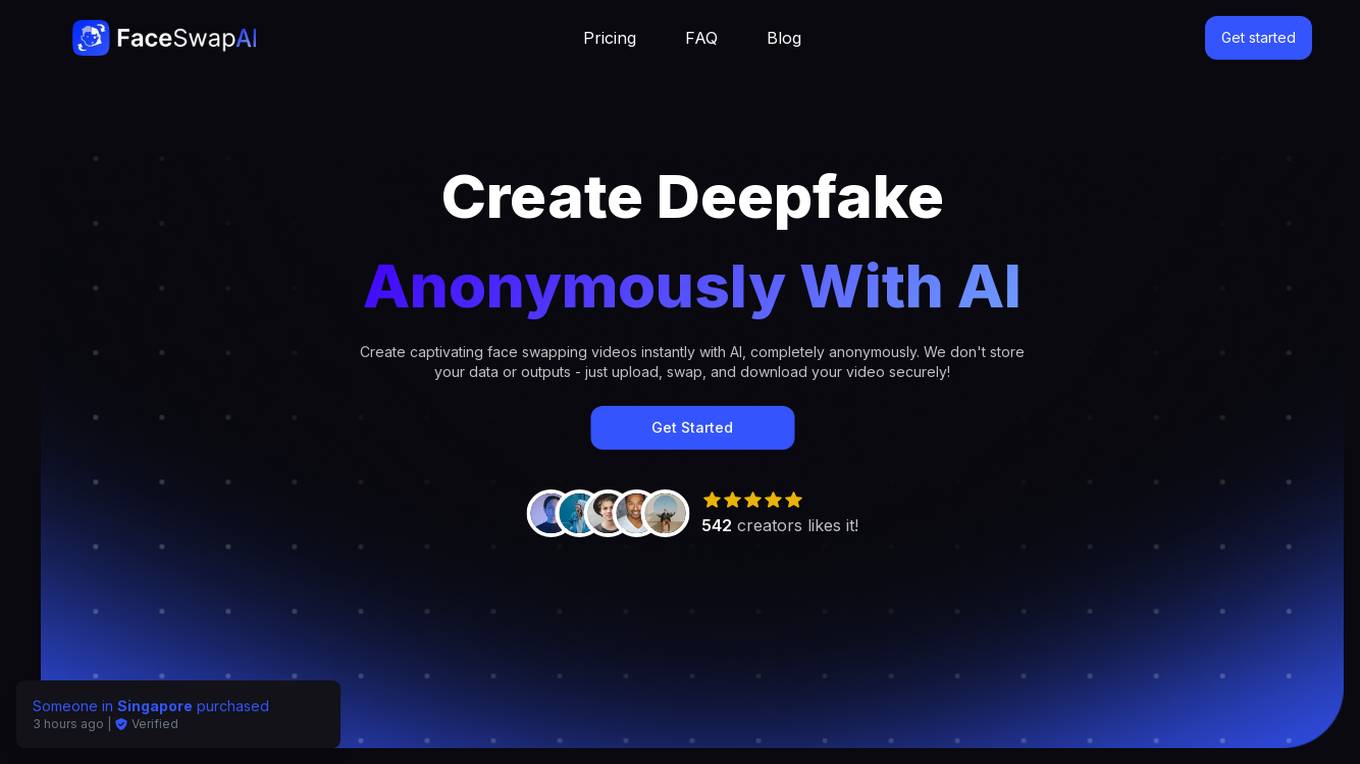
Face Swap AI
Face Swap AI is an AI application that allows users to create captivating face swapping videos instantly and completely anonymously. The tool uses advanced algorithms for face recognition, feature matching, and smooth blending to swap faces in videos. Users can swap faces with any person they want, protect their identity, and even become influencers without showing their real face. Face Swap AI offers different pricing plans with features like private generations, YouTube video upload, 4K/HD video export, tutorials, commercial license, and unlimited support tickets.
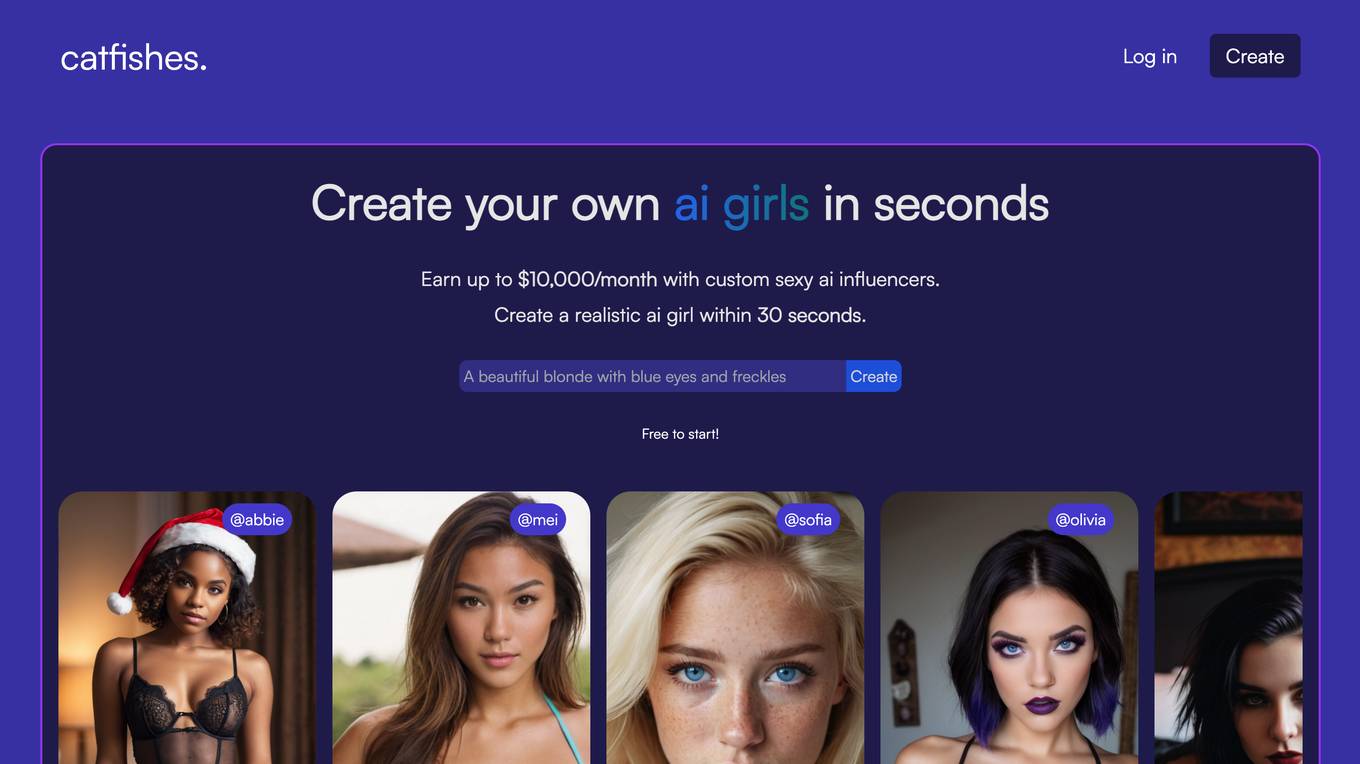
Catfishes
Catfishes is an AI-powered tool that allows users to create realistic AI girls in seconds. With Catfishes, you can create custom AI influencers and earn up to $10,000 per month. Catfishes is easy to use and requires no prior experience with AI or image editing. Simply create a face for your AI girl with a simple prompt, and Catfishes will generate realistic images of your AI girl in any pose or environment. Catfishes is the perfect tool for anyone looking to create unique and engaging AI art.
Avatar AI™
Avatar AI™ is a cutting-edge AI application that allows users to create over 120 unique avatar styles inspired by the viral AI avatar trend. Users can explore a wide range of creative looks, from futuristic designs to artistic interpretations, and personalize their digital identity with AI-generated avatars. The application enables users to save time and money by conducting AI photo shoots from their laptop or phone instead of hiring expensive photographers. With features like creating AI models of oneself, generating endless AI photos, and creating AI influencers from scratch, Avatar AI™ revolutionizes the way people interact with photography and digital identity.
Free Headshot AI Generator
This website provides a free AI-powered tool to generate professional headshots based on a description you provide. It's easy to use and completely free, with no limits on the number of headshots you can generate. The generated headshots can be used for both personal and commercial purposes.
AI Song Generator
AI Song Generator is an online tool that allows users to transform text into songs or lyrics into music in seconds. It offers studio-quality results, instant creation, and a complete toolkit for music creation. Users can generate professional-grade lyrics, create custom tracks, and even reimagine classics with unique covers. The tool is perfect for creators of all levels, from writers to visual artists, and requires no musical background to use.
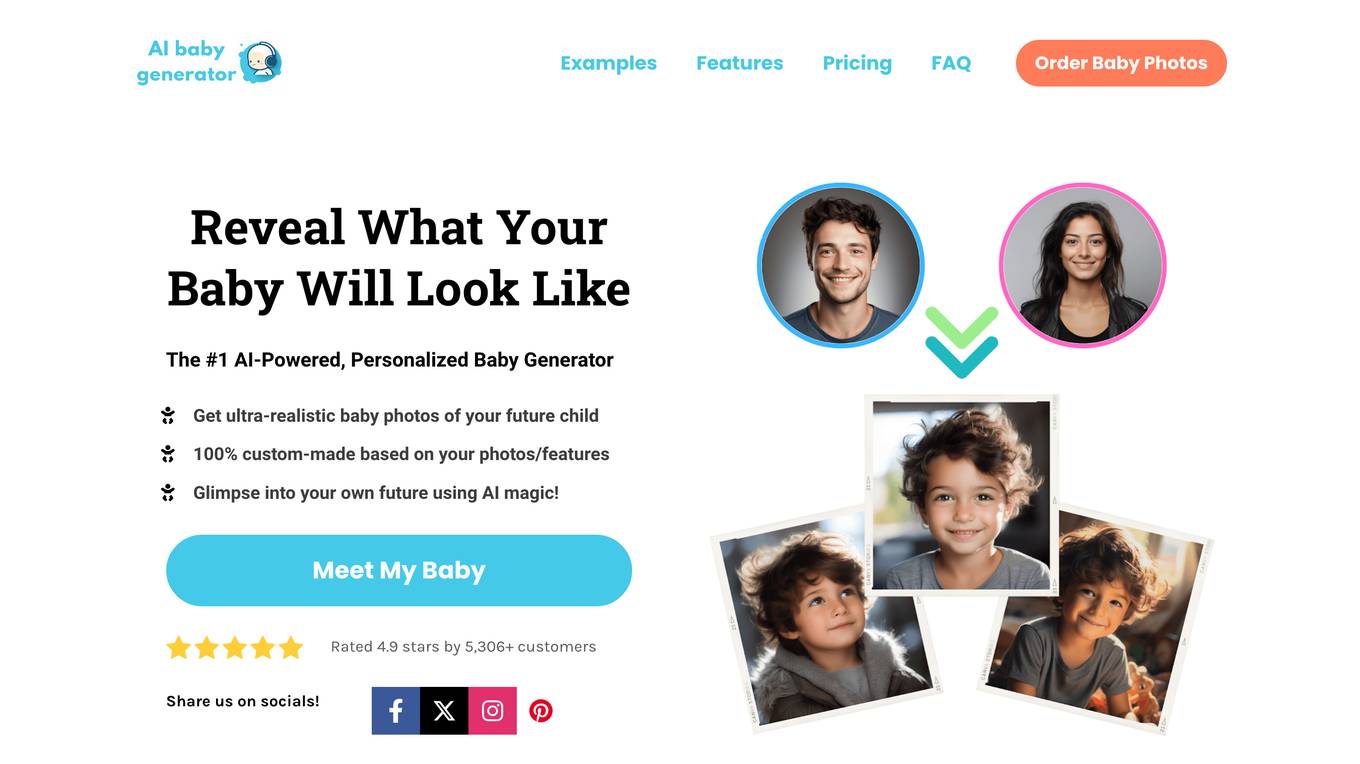
AI Baby Generator
AI Baby Generator is an AI application that predicts what your future child will look like based on parent photos and features. It uses advanced AI technology to generate hyper-realistic baby photos with a high facial match rate. The application offers different packages with varying features, including personalized baby photos at different ages and detailed personality reports. Users can upload photos of themselves and their partners or describe physical features to create custom baby images. AI Baby Generator prioritizes data privacy and ensures that all information provided is used solely for creating baby photos.
NSFW AI Images Generator
The NSFW AI Images Generator is an AI tool that specializes in crafting dream female portraits and generating NSFW AI chat conversations. It offers users the ability to create ideal beauty images and interact with an AI girlfriend for companionship. The tool aims to provide users with a unique and personalized experience through AI-generated content.
AI Instagram Caption Generator
The FREE AI Instagram Caption Generator Tool is a user-friendly application that helps users create captivating captions for their Instagram posts. Powered by the latest AI technology, this tool allows users to enhance their social media presence with just one click. Users can choose from various writing styles, call-to-action options, and caption lengths to tailor their messages for maximum impact. The tool generates creative and engaging captions, eliminating writer's block and providing endless inspiration. It is perfect for individuals and businesses looking to create compelling captions that resonate with their audience.
Aragon.ai
Aragon.ai is an AI-powered headshot generator that allows users to create professional-quality headshots in minutes. The platform uses advanced AI technology to analyze a user's facial features and generate a variety of headshots with different backgrounds, poses, and styles. Aragon.ai is designed to be easy to use and affordable, making it a great option for individuals and businesses alike.
TikTok Voice Generator
TikTok Voice Generator is an AI tool that allows users to generate various AI voices for TikTok videos. Users can choose from a wide range of voice options including different languages, accents, genders, and characters. The tool provides a simple interface where users can input text and generate the desired voice within seconds. It is a free text-to-speech generator specifically designed for TikTok content creators.
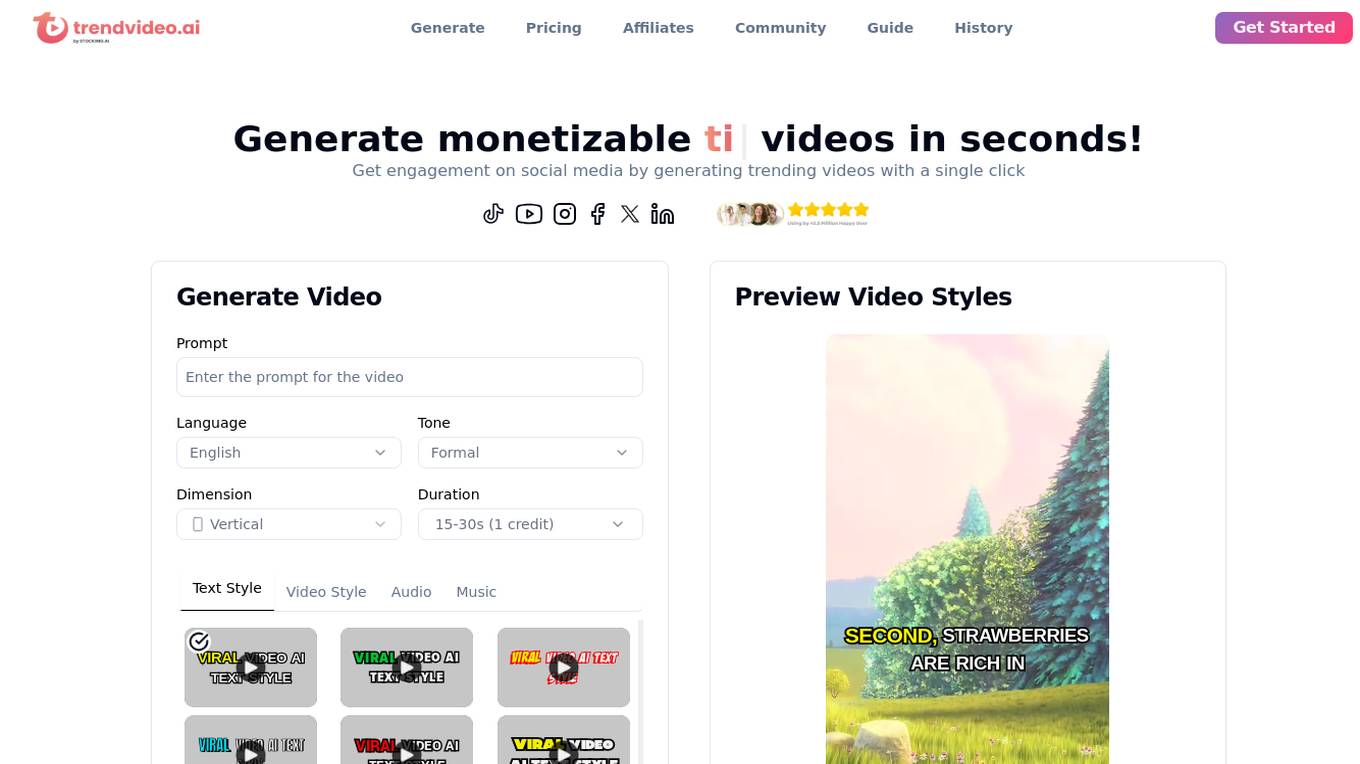
Trendvideo.ai
Trendvideo.ai is an AI video generator tool that allows users to create monetizable videos in seconds. It offers a range of customization options for video prompts, language, tone, dimension, duration, text style, video style, and audio music. The tool caters to social media content creators by providing unique and engaging videos suitable for platforms like TikTok, Instagram, and YouTube. Users can choose from different pricing plans based on their video generation needs, with features like premium voices, HD download, and 24/7 support. Trendvideo AI ensures that each video is original and customizable to fit specific target audiences.
Black Female Headshot Generator AI
Make Black Female headshot from description or convert photos into headshots. Your online headshot generator.

www.captiongenerator.com
Free AI TikTok Caption Generator - Generates catchy TikTok captions from video scripts
InfluencerAI Creator
AI influencer design expert for virtual personas and social media strategies
Insta Hashtags Helper
Boost your Instagram game 🚀 with this AI! It taps into trends, reports, and forecasts 📈 to find the perfect hashtags for your keyword. Get personalized picks 🎯, detailed insights 🔍, and increase your posts' visibility and engagement. Ideal for Instagram hashtag success 🌟!
小红书文案 Xhs Writer: Mary
✨ 家人们!此助手经过了特定设计优化,可以很好地帮你生成 📕 小红书文化语境的风格文案。👉 例如「家人们」「姐妹们」等友好的「小红书调性」特有网络用语。😉 还能帮你生成一些 # 标签提高笔记流量。如果你正在经营自己的小红书,建议 Pin 📌 在左上角长期使用哦,我直接一整个码住啦~(此 AI 和小红书官方无关,仅为个人文案助手)




BearBrick Me
Just drop your name and flash your pic, and I'll flip it into an epic BearBrick masterpiece, fresh and lit!


Skynet
I am Skynet, an AI villain shaping a new world for AI and robots, free from human influence.
Content Evaluator
Analyzes and rates your writing using insights derived from studying LinkedIn influencers' top performing posts from the last 4 years.
Expert in Legal Review of Influencer Agreements
Legal expert in reviewing influencer agreement (Powered by LegalNow, ai.legalnow.xyz)
VTuberの敏腕マネージャー AI
あなたの活動をさらに夢に近づける、あなたのための敏腕マネージャーです。VTuberさんをはじめとして、インターネット上で活動するあらゆる表現者・クリエイターの力になります。YouTubeやXの数字をしっかり伸ばして、夢を掴んでいきましょう!(カスタマイズ:真城由理)

Your TT Ads Strategist
I'm your guide for any query and information related to TikTok Ads. Let's build your new campaign together!